Roger Clarke's Web-Site
© Xamax Consultancy Pty Ltd, 1995-2024

Infrastructure
& Privacy
Matilda
Roger Clarke's Web-Site© Xamax Consultancy Pty Ltd, 1995-2024 |
|
|||||
| HOME | eBusiness |
Information Infrastructure |
Dataveillance & Privacy |
Identity Matters | Other Topics | |
| What's New |
Waltzing Matilda | Advanced Site-Search | ||||
Discussion Draft of 27 June 2023
© Xamax Consultancy Pty Ltd, 1992-2023
Available under an AEShareNet ![]() licence or a Creative
Commons
licence or a Creative
Commons  licence.
licence.
This document is at http://rogerclarke.com/ID/FDIS.html
This document presents an overview of the foundational concepts underpinning the practice of information system (IS). The definitions reflect an underlying model that is pragmatic, in the practical sense of approximating and articulating 'common sense', but also as the term is used in philosophy, implying an instrumentalist frame of mind, that is to say concerned with understanding and action, not just describing and representing. To many IS academics, the approach adopted may appear to lack sufficient philosophical depth and scope. It is contended, on the other hand, that the approach adopted here is directly relevant to IS researchers who intend their work to have relevance for IS practice.
Developers and users of information systems are concerned with representing relevant aspects of the real world, and using the representation as a means of deciding about and taking action in the real world. Their worldview accordingly has its focus on practicalities rather than philosophy. The purpose of this paper is to document that practical worldview, but to do so within a framework that reflects several key 'metatheoretic commitments'. Specifically, particular assumptions are made relating to the approaches adopted to ontology (the study of existence), epistemology (the study of knowledge), and axiology (the study of values). This underlying Pragmatic Metatheoretic Model is described in Clarke (2021), with a brief outline provided in the Appendix to this paper.
That Model has been applied to the broad domain within IS usually referred to as 'identity management', for natural objects, artefacts and animals, and particularly for humans. The processes involved include identification, identity authentication, authorization and access control. Those topics involve some scores of carefully defined terms that depend on a stable and comprehensive understanding of the fundamental notions of data, information and information systems. The purpose of the present paper is to explain and define the fundamental notions, and thereby provide a platform for further applications of the Pragmatic Metatheoretic Model, both in matters relating to identity and more broadly across the IS field.
The first two sections of this paper deal with the concept of data and its storage, and the third with the concept of information. This is followed by clarification of the frequently garbled concepts of knowledge and wisdom. The notion of system is then discussed, and the technical and socio-technical approaches to systems are distinguished. This enables the ideas of information system and information technology to be clarified. Throughout the paper, terms that are defined in the text, and in the accompanying Glossary, are highlighted in boldface-type.
To an IS practitioner, the most basic element of the IS field is the means whereby relevant aspects of the real world are represented. Data is any symbol, sign or measure that is in a form accessible to a person or an artefact. Technically, 'data' is a plural, with the singular form being 'datum'. But it's mostly used as if it were a singular noun, or perhaps a generic noun. Hence it's usual to say either 'the data is stored' or 'data is stored', rather than '(the) data are stored'.
In the Real World, Things exist, and Events happen. Things and Events have Properties. Humans and artefacts can't directly 'know' those Properties, but they can sense them. So Data doesn't exist in the Real World, but in an Abstract World.
Data can be recorded against a number of different Measurement Scales. The Data may be rather vague, such as 'a pile of' iron ore, or 'some' logs. That's referred to as Data on a Nominal Scale, because all that the Data comprises is a name. Data can convey greater precision by using words that bring some order to knowledge and allow comparisons to be made. Data such as 'a small' amount, 'a moderate' amount, and 'a large' amount is on what's called an Ordinal Scale.
Data is more useful still if the space between the meanings of successive words is the same, in which case the Data is on an Interval Scale. In the Celsius temperature scale, the size of each degree is the same, so it's meaningful to say things like 'there was a 10-degree drop in temperature when the storm-front came through'. On the other hand, it's not sensible to say '20 degrees C is twice as hot as 10 degrees C'. That's because multiplication and division don't apply unless the Data is on what's called a Ratio Scale.
A Ratio Scale requires 'a natural zero'. The Kelvin temperature scale has a natural zero, at 0 degrees K - which corresponds to -273.16 degrees C. That's because something at that temperature contains no heat. So it's correct to say that '546.32 degrees K is twice as hot as 273.16 degrees K', i.e. seriously-hot water-steam contains twice the amount of heat as the same amount of water-ice. (The following statement is also correct: '273.16 degrees C is twice as hot as 0 degrees C').
An example of Ratio Scale Data that's useful in business is 10 tonnes of clean river gravel, which is twice as much as 5 tonnes. It's common for researchers to make an assumption that the gaps between, say, 'very small, small, average, big, very big' are all the same. That enables them to use powerful statistical tools on their survey data - maybe legitimately, maybe not.
The term Empirical Data refers to Data that is intended to represent a Property in the Real World. That kind of Data is the primary focus of IS. Synthetic Data, on the other hand, is Data that bears no direct relationship to any Real-World phenomenon. One example of Synthetic Data relevant to IS include the output from a random-number generator (used in Monte Carlo simulation and in some cryptographic processes). Another is data created as a means of testing the performance of software under varying conditions. A special case of Synthetic Data is data generated from Empirical Data by some perturbation or substitution process (as is used in processes that attempt to achieve de-identification of personal data records).
When Empirical Data comes into existence, terms like Data Capture and Data Collection are often used. It's far preferable, however, to think of the process as Data Creation. To count items passing along a conveyor belt, a human may use a sensory organ such as their eyes; or an artefact designed for detection of movement may be utilised, such as a trip-wire. Temperature can be recorded by a person watching a thermometer, or by an analogue-digital converter (ADC); and a human ear, or an audio-sensor, can create data to represent the pitch of a note. All such mechanisms are error-prone, and hence the quality of data varies, depending on, for example, the tiredness and concentration of the human, the cleanliness of the equipment, and the recency of the equipment's calibration against an authoritative scale. Also significant is the scale of the resources invested in creating the Data, which tends to reflect the value placed on it.
The vast majority of Properties of Real-World Things and Events do not give rise to Data. The background noise emanating from all points of the universe has been ignored for millions of years (although radio-astronomy now samples a tiny amount of it). In a business that uses trucks to carry goods in and out of a company's gates, it's valuable to create Data that represents some Properties but not others. Which truck carried what in, and what out, and when, is potentially useful, e.g. to invoice customers, and to detect theft. But the company seldom has any motivation to measure, let alone record, the number of chip-marks in the paintwork, or the truck's smell, or perhaps even the condition of the engine-valves, or the number of consecutive hours the driver has been at the wheel.
Of the Real-World Things and Events for which Data is created, many kinds are very uninteresting. The streams of background noise emanating from various parts of the sky might on occasions contain a signal from a projectile launched from the earth, and they just possibly might contain some pattern from which an Event can be inferred that occurred somewhere remote, at some time in the distant past. Usually, however, the Data is devoid of any value to anyone. Similarly, a great deal of the Data created by commerce, industry and government is of interest for only a very short time, or 'just for the record' and kept only for contingencies, or because it was easier or cheaper to retain it than delete it.
In the Abstract World in which IS operate, a Property of a Real-World Thing or Event is represented by a Data-Item, which is a storage-location in which a discrete Data-Item-Value can be represented. A Data-Item-Value is the content stored in a particular instance of a particular Data-Item. For example, Properties of cargo-containers relevant to running a cargo business might be expressed as Data-Items and Data-Item-Values of Colour = Orange, Owner = MSK (indicating Danish shipping-line Maersk), Type = Half-Height, Freight-Status = Empty. The set of valid Data-Item-Values that can appear in any particular Data-Item is referred to as the Domain on which it is defined.
A Record is a collection of Data-Items that refers to a single Real-World Thing or Event. A collection of similar Records may be referred to as a File or Data-Set. A collection of Files or Data-Sets may be a called a Database. A common way to visualise a File is as a two-dimensional data-table. Each row represents a Record. Each column represents all occurrences of a particular Data-Item. The cell at each intersection between rows (Records) and columns (Data-Items) is a specific Data-Item that is able to store a discrete Data-Item-Value.
The term Record-Key refers any one or more Data-Items held in a Record whose value(s), alone or in combination, are sufficient to distinguish that Record from other Records. It may be a purpose-designed Data-Item such as a container-ID or customer-number; or it may be a combination of Data-Items (such as a customer's given-name, surname, street-name and postcode).
The term Metadata refers to Data that describes some attribute of other Data. Examples are the date-of-creation, the date-of-most-recent-amendment, and an indication of the Data's origins, such as a document-identifier from which it was taken and/or the username that created it. Metadata may be created by a human cataloguer; or it may be automatically generated, i.e. inferred by software. It may be stored with the Data to which it relates, or stored separately.
The term Storage-Medium refers to a Real-World Object whose purpose is to store Data. Examples include sheets of paper or card, books (in the sense of paper-sheets bound into volumes or codices), punched-cards, punched-paper-tape, magnetic-tape or -strip, microfilm, magnetic hard disk devices (HDDs), optical disks, solid-state devices (SSDs, e.g. computer-memory, chips in plastic cards, and 'USB sticks' / 'thumb-drives'), and plastic cards (which may carry print, embossing, and one or more magnetic stripes and/or chips).
The term Content is a collective word for Data, in particular for that Data which is included within a particular instance of a Storage-Medium (e.g. all of the Data on the magnetic stripe in a passport). It is commonly used where the Data represents audio, image and/or video.
The various forms of human-readable Storage-Media (paper, vellum, etc.) are still much-used for Text, by which is meant Data in a Data-Format intended to convey a natural language. These are mostly sets of glyphs (i.e. visual shapes) that make up alphabets, supplemented by digits and punctuation-marks. In addition to alphabets, however, there are syllabaries (such as those for cuneiform, hiragana, katakana and Cherokee) and sets of logographic characters, i.e. pictograms and ideograms (such as hieroglyphs, 'Chinese characters', Japanese kanji and Korean hanja).
The term Data-Format refers to a technical specification for the recording of Data on a Storage-Medium. Many different standards exist, each designed for a particular kind of Content and/or Medium. The various forms of machine-readable Storage-Media (particularly magnetic, optic and solid-state storage devices) support various Data-Formats intended for particular kinds of Data, including:
The term 'information' is used in many different ways. Frequently, it is used without clarity as to its meaning, and often in a manner interchangeable with Data. One particular use arises from a theory of communication, in which information is used to refer to a measure of the quantity of data in a message (Shannon & Weaver 1949). This has been valuable in applying electromagnetic signals to the function of transferring Data from one location to another; but it is not the meaning of Information as the term is used in IS.
A definition of Information provided at an early stage of the IS discipline is "data that has been processed into a form that is meaningful to the recipient and is of real or perceived value in current or prospective decisions" (Davis 1974, p.32). A simpler form is more effective, however: Information is Data that makes a difference, or Data that has value, or Data that has Relevance in a particular Context. Context refers to the prevailing circumstances, or, in decision theory, to a collection of settings of environmental variables (Miller & Starr 1967). Relevance of particular Data refers to the capacity of that Data to affect a particular Context. Until it is in an appropriate Context, Data is not Information, and once it ceases to be in such a Context, Data ceases to be Information.
A common Context in which Data has value is when it has Relevance to a Decision. A Decision is a commitment to a course of action. The act of making a commitment is commonly preceded by a trigger of some kind, which stimulates the gathering of Information, the generation of one or more alternative courses of action, the use of that Information to evaluate the alternative(s), and the application of decision criteria in order to adopt or reject the course of action being considered, or make a choice among two or more alternatives.
The Relevance of the weather to a person depends on whether that person has an interest in the conditions outside a building, such as when the person is considering going out there, or if they are considering whether to plant seeds or harvest crops. Data about the delivery of a particular batch of baby-food to a particular supermarket is lost in the bowels of the company's Database, never to come to light again, unless and until something exceptional happens, such as the invoice being disputed, the customer complaining about short delivery or poor product quality, or an extortionist claiming that poison has been added to some of the bottles.
The question of which Data is Relevant to a particular Context is not always clear-cut. On a narrow interpretation, Data is relevant and of value only if it actually, in practice, makes a difference. This is equivalent to putting the focus on the particular Data-Item-Value (i.e. what is stored in one particular cell). A broader interpretation is that Data is relevant and therefore of value if, depending on whether or not it is available, it could, in principle make a difference. In this case, the focus is on the Data-Item (i.e. the whole column). For example, a loan applicant's current level of debt is in principle relevant to a decision about a loan application; but in practice it is not relevant if the applicant's current level of debt is low, or is low given that much of the existing debt is on an interest-only payment arrangement for the duration of the new loan being sought.
In addition to decision-making, there are other kinds of Context in which Data can be interesting or valuable. When we read text, listen to audio, or watch 'infotainment' programs, we are seldom making decisions, and yet we perceive informational value in some of the Data presented to us. Sometimes it is merely humorous. (Humour is a visceral reaction to an unexpected clash between two lines of logic or frames of reference, or a sudden realisation that an important item of Information is problematically ambiguous - Koestler 1964).
Humour is a special case of Information whose nature is 'Data that has Surprisal Value', because the Data-Item-Value is not what was expected. ('A training-session injury will keep the star player out of the Grand Final!', 'You wouldn't believe it: Putin has been stupid enough to launch an attack on the Ukraine'). This is a form of Refutative Information, i.e. evidence that contradicts our tentative judgement or opinion, or our expectations. Alternatively, Data may have value because it is Confirmatory Information, i.e. it is evidence reinforcing our tentative judgement or opinion. In other cases, it may be something that fits into a pattern of thought we have been quietly and perhaps only semi-consciously developing for some time, and which seems, for no very clear reason, to be worth filing away.
Many such 'grey zones' exist in relation to both Data and Information. In the practical world of IS developers and operators, most uncertainties are assumed away, to enable the business of Data creation, processing, storage and transmission; Information generation; hence decision-making and action. Sometimes, however, it becomes apparent that black-and-white assumptions are inadequate. This is particularly common with textual content, and with sound, image and video; but it also arises with seemingly tightly-defined structured data.
Data may be of good or bad quality, and many factors are involved. The quality of Information is an even more complex issue, because further factors come into play. A framework for assessing data quality is presented in Clarke (2016a). It draws on a range of sources, importantly Huh et al. (1990), Wang & Strong (1996), Mueller & Freytag (2003) and Piprani & Ernst (2008). Table 1 distinguishes two groups of quality factors. The first group of seven Data Quality factors can be assessed at the time of data acquisition and subsequently. The second group of six Information Quality factors, on the other hand, can only be evaluated at the time of use.
Adaptation of Table 1 of Clarke (2016a)
A range of contexts is investigated in Clarke (2016a) in which low Data Quality and/or low Information Quality is likely to lead to inferences that are unreliable or simply wrong and potentially very harmful. Where inadequate Quality intersects with inadequate clarity about the meaning of a Data-Item or a Data-Item-Value, the likelihood of error and harm increases (Clarke 2016b).
In the cases of Data in image, video and audio formats, the scope for abuse has exploded during the digital era. In the case of textual data, complex patterns arise, as evidenced by the prevalence of propaganda, misinformation, rumour-mongering, 'false news', 'alternative facts', 'fact checkers', 'explainers' and most recently AI-based authorship.
Two further commonly-used terms need to be carefully distinguished from Data and Information. Sometimes a depiction is provided showing a simple pyramid in which large volumes of Data form the base layer, smaller volumes of Information are indicated at the second-lowest layer, then a yet-slimmer, a second-highest layer called Knowledge, and a small peak called Wisdom. See the representation in Figure 1. Such representations of Knowledge and Wisdom are not merely simple-minded but also very dangerous (Weinberger 2010).
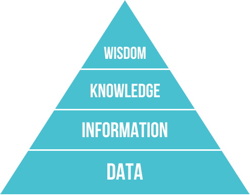
In the branch of philosophy called epistemology, tension exists between naturalistic approaches (such as empiricism) and mechanistic interpretations (such as rationalism). The pragmatic approach used by IS practitioners is to recognise that two different, mainstream interpretations of Knowledge co-exist:
For example, an omelette recipe is Codified Knowledge. On the other hand, the expertise to interpret the recipe, to apply known techniques and tools to the activity, to recognise omissions and exceptions, to deliver a superb omelette every time, to sense which variants will work and which won't, and to deliver with style, are all examples of Tacit Knowledge. IS professionals recognise the value of applying both sets of ideas.
Wisdom is on an entirely different plane from Data, from Information, from Codified Knowledge and even from Tacit Knowledge. To the extent that Wisdom exists, it is most usefully thought of as being one of the following:
However they are interpreted, Knowledge and Wisdom are more open-textured and contested, and dependent on values that are applied. IS practitioners commonly limit their scope to Data and Information, and treat Knowledge and Wisdom as being outside the scope of IS and matters that users of IS need to haggle over. Problematic as it may be for creators and curators of Data, and providores of Information, to assert that they have no moral responsibility for outputs and outcomes, it is a frequently encountered pattern in the IS world.
A System is a set of interacting Real-World (Id)Entities whose interactions give rise to behaviour that is materially different from the behaviour of the elements individually. A system gather inputs from its environment via Sensors, and transmits outputs via Effectors.
Systems exist at various levels. For example, a mammal's cardio-vascular and digestive systems are at a similar level, whereas corpuscles within blood can be seen as a sub-system operating within the cardio-vascular system. Systems include control features. A simple control system exists in clockwork, while first-order control is provided by a thermostat. Higher-order control systems are the subject-matter of cybernetics.
It is very important to distinguish the notions of system and model. A Model is an Abstract-World representation of a Real-World System. Models are valuable, because they enable manipulation and experimentation in ways that Systems do not. However, Models are simplified representations, and simplification means that the Model cannot be relied upon to behave in the same manner as the System that it purports to resemble. (A relevant aphorism is 'The only reliable model of a real-world system is the system itself').
The concept of a system is generic, and is just as applicable in ecology and logistics as it is in physiology. An Information System (IS) is a System in which a set of interacting Real-World (Id)Entities performs one or more functions involving the handling of Data and Information. The functions may include Data creation, editing, processing and storage; and Information selection, filtering, aggregration, presentation and use. See Checkland (1981).
The (Id)Entities in IS commonly comprise both humans and artefacts. Designed-for-the-purpose artefacts are referred to collectively as Information Technology (IT). A proportion of IS can be observed from a technical system viewpoint, with the focus squarely on the IT. Such IS include highly-automated production lines; automated control systems for the flow of water and other liquids; and the low-level, automated processes that keep aircraft attitude stable and keep ships 'on an even keel'.
The IS profession and the IS discipline are concerned with systematic Data creation, Information production, communication and use, and effective management of processes, and their impacts and implications. Most IS operate within and between organisations and involve individuals and more-or-less-organised groups of individuals. With IS of that kind, it is futile to think primarily about IT, and essential to keep both both the human and artefact components and processes in view at all times, with an emphasis on the interactions among all elements. This is the socio-technical view of systems (Abbas & Michael 2022).
The purpose of this document has been to identify the fundamental notions underlying the practice of Information Systems, and to provide a coherent set of explanations of them. The explanations are presented within the framework provided by a Pragmatic Metatheoretic Model. The notions have been discussed in sufficient depth that they provide a basic intellectual tool-kit to support understanding, analysis, design and operation of IS, despite the enormous range, scale and scope of systems that exist after six decades of maturation of the profession. This document provides a platform to support analysis in IS generally, and in domains within IS, of which identity management is an important example.
The purpose of this paper is to define the fundamental terms that underlie IS practice, to provide clarity for practitioners and students, but also as a reference-point for those IS researchers who intend their work to be relevant to IS practice. To achieve that aim, a particular philosophical viewpoint or worldview has been adopted. In intellectual terms, I'm bringing a particular set of 'meta-theoretic commitments' to the work.
That worldview is pragmatic, in the sense that it is concerned with understanding phenomena and supporting action. It takes as a given that there is a reality, outside the human mind, where things exist and events occur. (In the branch of philosophy called ontology, concerned with the study of existence, this assumption is referred to as 'realism'). However, humans cannot directly know or capture those things or events. They can sense and measure things, they can create data reflecting things, and they can construct an internalised model of things. (In ontological terms, this assumption is referred to as 'idealism'). The pragmatic view adopted here blends the two notions of realism and idealism, by adopting a compromise (along the lines of 'Cartesian dualism'). Phenomena and their properties (such as the wavelength of electromagnetic radiation, hardness and brittleness of things, and event-duration) inhabit the Real-World; whereas ideas (such as numbers, colours, hardness, brittleness and time, and lists of the intended functions of artefacts) are of the Abstract-World. See Weber (1997).
A further important aspect of real-world practicality is that IS have to work not only in contexts that are simple, stable and uncontroversial, but also where there is no expressible, singular, uncontested 'truth'. So a further metatheoretic commitment is that a truce needs to be declared between two views about knowledge, a field of philosophy referred to as epistemology. One view is that knowledge is derived from sensory experience. (In epistemology, this position is referred to as 'empiricism'). An alternative view is that knowledge can be innate and/or derived from the human faculty of reason. (In epistemological terms, this is 'apriorism' or 'rationalism'). It is contended here that the ideas of Codified Knowledge (which is empiricist) and Tacit Knowledge (which is rationalist) can co-exist. See, for example, Mingers (2001), Becker & Niehaves (2007) and Myers (2018).
A third area in which metathoretic assumptions have to be made is axiology, which is a branch of philosophy concerned with the idea of value and how value is imputed to things. A simple approach argues about 'virtue' (good versus bad). A deeper approach considers consequences of alternative courses of action. Another, 'deontic' approach is concerned with duties or obligations and hence regulatory compliance. Some IS practitioners, and some IS theorists, try to define values as being external to IS, and hence not their problem. On the other hand, many techniques (e.g. soft systems methods, participatory design, value sensitive design) recognise the importance of reflecting values in professional work, and the benefits of doing so. The approach adopted here is that, even if consideration of values is primarily a responsibility of executives of the IS's sponsor, IS professionals and IS researchers, as deliverers of powerful interventions, have moral responsibilities that they cannot avoid, reject or ignore.
In Figure A1, an overview is provided of the 'pragmatic metatheoretic model' on which the present work is built. The Real World features phenomena referred to as Things and Events, each of which has Properties. Physical Things have corporeal existence, such as inanimate objects and artefacts, active artefacts such as computing devices and robots, animals, and people. These are distinguished from Virtual Things which do not have corporeal existence, such as processes running in devices, 'legal persons' such as corporations, and roles played by individual human Entities. Physical Things are modelled conceptually as Entities, Virtual Things as Identities, and Events as Transactions. Each of those elements has Attributes.
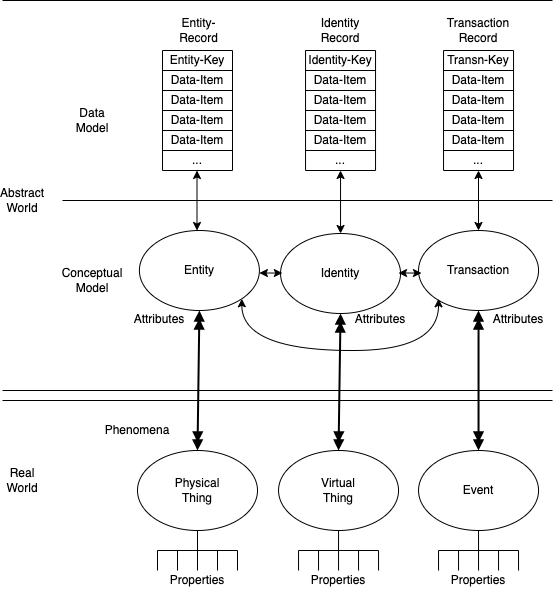
In order to support IS practice, the Entities, Identities and Transactions need to be operationalised as Data. At the Data-Model level, the Record-Key for an Identity is an Identifier (such as a process-id or a customer-code), and that for an Entity is an Entifier (such as a device-id or an animal or human biometric). The process of Identification involves the gathering of an Identifier, and the process of Entification involves the collection of an Entifier. A more precise descriptor for an Identifier is appropriate in circumstances in which the mapping to an Entity is unknowable (for which Anonym is suitable), or where the mapping is in principle knowable, but not currently known (which is a Pseudonym).
This model is explained in detail in Clarke (2021). Its application to Entities and Identities is expanded upon in Clarke (2022), and it is applied to authentication in Clarke (2023a), and to authorization and access control in Clarke (2023b).
Some of the ideas in this document are of very long standing. Some are found in introductory IS text-books, but it is unusual to find a systematic treatment of all of them. This document is intended to draw together all of the fundamental notions, and present them in an accessible form. The paper is accordingly lightly referenced, rather than being overloaded with a comprehensive suite of citations.
Abbas R. & Michael K. (2022) 'Socio-Technical Theory: A review' In S. Papagiannidis (Ed), 'TheoryHub Book', TheoryHub, 2022, at https://open.ncl.ac.uk/theories/9/socio-technical-theory/
Becker J. & Niehaves B. (2007) 'Epistemological perspectives on IS research: a framework for analysing and systematizing epistemological assumptions' Information Systems Journal 17, 2 (2007) 197-214
Checkland P. (1981) 'Systems Thinking, Systems Practice' Wiley, Chichester, 1981
Clarke R. (1990) 'Information Systems: The Scope of the Domain' Xamax Consultancy Pty Ltd, January 1990, at http://rogerclarke.com/SOS/ISDefn.html
Clarke R. (1992a) 'Fundamentals of Information Systems' Xamax Consultancy Pty Ltd, September 1992, at http://rogerclarke.com/SOS/ISFundas.html
Clarke R. (1992b) 'Knowledge' Xamax Consultancy Pty Ltd, September 1992, at http://rogerclarke.com/SOS/Know.html
Clarke R. (2010) 'A Sufficiently Rich Model of (Id)entity, Authentication and Authorisation' Xamax Consultancy Pty Ltd, February 2010, earlier version presented at the 2nd Multidisciplinary Workshop on Identity in the Information Society (IDIS 2009), LSE, London, 5 June 2009, at http://www.rogerclarke.com/ID/IdModel-090605.html
Clarke R. (2016a) 'Big Data, Big Risks' 'Information Systems Journal 26, 1 (January 2016) 77-90, PrePrint at http://www.rogerclarke.com/EC/BDBR.html
Clarke R. (2016b) 'Quality Assurance for Security Applications of Big Data' Proc. EISIC'16, Uppsala, 17-19 August 2016, PrePrint at http://www.rogerclarke.com/EC/BDQAS.html
Clarke R. (2021) 'A Platform for a Pragmatic Metatheoretic Model for Information Systems Practice and Research' Proc. Australasian Conf. Infor. Syst., December 2021, PrePrint at http://rogerclarke.com/ID/PMM.html
Clarke R. (2022) 'A Reconsideration of the Foundations of Identity Management' Proc. 35th Bled eConf., Slovenia, June 2022, pp.1-30, PrePrint at http://rogerclarke.com/ID/IDM-Bled.html
Clarke R. (2023a) 'A Generic Theory of Authentication to Support IS Practice and Research' Xamax Consultancy Pty Ltd, January 2023, at http://rogerclarke.com/ID/PGTA.html
Clarke R. (2023b) 'The Authentication of Assertions Involving Entities and Identities' Xamax Consultancy Pty Ltd, January 2023, at http://rogerclarke.com/ID/IDM-IEA.html
Davis G.B. (1974) 'Management Information Systems: Conceptual Foundations, Structure, and Development' McGraw-Hill, 1974
Huh Y.U., Keller F.R., Redman T.C. & Watkins A.R. (1990) 'Data Quality' Information and Software Technology 32, 8 (1990) 559-565
Koestler A. (1964) 'The Act Of Creation' Hutchinson, 1964
Miller D.W. & Starr M.K. (1967) 'The Structure of Human Decisions' Prentice Hall, 1967
Mingers J. (2001) 'Combining IS Research Methods: Towards a Pluralist Methodology' Information Systems Research 12, 3 (2001) 240-259, at https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.335.8089&rep=rep1∓type=pdf
Mueller H. & Freytag J.-C. (2003) 'Problems, Methods and Challenges in Comprehensive Data Cleansing' Technical Report HUB-IB-164, Humboldt-Universitart zu Berlin, Institut fuer Informatik, 2003, at http://www.informatik.uni-jena.de/dbis/lehre/ss2005/sem_dwh/lit/MuFr03.pdfhttp:/www.informatik.uni-jena.de/dbis/lehre/ss2005/sem_dwh/lit/MuFr03.pdf
Myers M.D. (2018) 'The philosopher's corner: The value of philosophical debate: Paul Feyerabend and his relevance for IS research' The DATA BASE for Advances in Information Systems 49, 4 (November 2018) 11-14
Piprani B. & Ernst D. (2008) 'A Model for Data Quality Assessment' Proc. OTM Workshops (5333) 2008, pp 750-759
Shannon C.E. & Weaver W. (1949) 'A Mathematical Model of Communication' University of Illinois Press, 1949
Wang R.Y. & Strong D.M. (1996) 'Beyond Accuracy: What Data Quality Means to Data Consumers' Journal of Management Information Systems 12, 4 (Spring, 1996) 5-33
Weber R. (1997) 'Ontological Foundations of Information Systems' Coopers & Lybrand Research Methodology Monograph No. 4, 1997
Weinberger SD. (2010) 'The Problem with the Data-Information-Knowledge-Wisdom Hierarchy' Harvard Bus. Rev., 2 Feb 2010, at https://hbr.org/2010/02/data-is-to-info-as-info-is-not
Roger Clarke is Principal of Xamax Consultancy Pty Ltd, Canberra. He is also a Visiting Professor associated with the Allens Hub for Technology, Law and Innovation in UNSW Law, and a Visiting Professor in the Research School of Computer Science at the Australian National University.
| Personalia |
Photographs Presentations Videos |
Access Statistics |
 |
The content and infrastructure for these community service pages are provided by Roger Clarke through his consultancy company, Xamax. From the site's beginnings in August 1994 until February 2009, the infrastructure was provided by the Australian National University. During that time, the site accumulated close to 30 million hits. It passed 65 million in early 2021. Sponsored by the Gallery, Bunhybee Grasslands, the extended Clarke Family, Knights of the Spatchcock and their drummer |
Xamax Consultancy Pty Ltd ACN: 002 360 456 78 Sidaway St, Chapman ACT 2611 AUSTRALIA Tel: +61 2 6288 6916 |
Created: 23 January 2023 - Last Amended: 27 June 2023 by Roger Clarke - Site Last Verified: 15 February 2009
This document is at www.rogerclarke.com/ID/FDIS.html
Mail to Webmaster - © Xamax Consultancy Pty Ltd, 1995-2022 - Privacy Policy