Roger Clarke's Web-Site
© Xamax Consultancy Pty Ltd, 1995-2024

Infrastructure
& Privacy
Matilda
Roger Clarke's Web-Site© Xamax Consultancy Pty Ltd, 1995-2024 |
|
|||||
| HOME | eBusiness |
Information Infrastructure |
Dataveillance & Privacy |
Identity Matters | Other Topics | |
| What's New |
Waltzing Matilda | Advanced Site-Search | ||||
Principal, Xamax Consultancy Pty Ltd, Canberra
Visiting Fellow, Department of Computer Science, Australian National University
Version of 2 October 2001, with minor revisions 2 June 2002
© Xamax Consultancy Pty Ltd, 2001-02
This document is at http://www.rogerclarke.com/II/DefWeb01.html
This document has been translated into Belorussian by Michail Bogdanov, at http://webhostinggeeks.com/science/def-web01-be (Dec 2011)
This document has been translated into Russian by Sandi Wolf, at http://www.opensourceinitiative.net/edu/DefWeb01/ (Mar 2019)
New technologies challenge old laws. A specific instance of concern arises in relation to defamation laws, because they represent a potentially significant constraint on the freedom of information flows. Courts around the world have yet to determine their stance in relation to the critical question of where a web-page is deemed, for the purposes of defamation law, to be published.
If the criterion used is the location of the web-server, or the location of the person who causes the upload of the page to the web-server, then publishers are in a position to assess the risks involved in publishing web-pages. If, on the other hand, the criterion used is the location of each web-browser that downloads the page, then publishers would be subject to the laws of every one of the perhaps 300 relevant jurisdictions in the world. That would impose impossible constraints on publishers, and seriously affect the availability of information.
I've been called upon on a couple of occasions to provide expert testimony relating to defamation on the web. The key question is whether the act of placing a document on a web-site constitutes publication in the jurisdictions into which the document is subsequently downloaded. This document presents my analysis.
It commences with several introductory sections that could be skipped by readers with appropriate background, They are designed to provide the court with background information and definitions relating to:
The analysis is then presented, under the following headings:
The Internet (sometimes abbreviated to Òthe `netÓ) is a telecommunications network that links other telecommunication networks. Its purpose is to enable computers that are attached to any Internet-connected network to communicate with one another.
Expressed a little more formally, the Internet is a network of computer networks, which enables messages to be transmitted between computers attached to any of those networks, using a common set of `communications protocols', or sets of operating rules.
Each network comprises `addressable devices' or `nodes' (i.e. computers) connected by `arcs' (i.e. communications channels). Each node may fulfil multiple roles. Each role is performed by a particular piece of software. A piece of software that initiates an interaction between two nodes is called a `client'; and a piece of software that responds is called a `server'. The computer on which a client or a server runs is commonly referred to as a `host'.
Each of the roles that a host performs is identified by an Internet Protocol address or `IP-address'. An IP-address is a 32-bit number. For convenience and human readability, that number is usually expressed as a 4-part group of decimal numbers, with each part consisting of an 8 bit number (i.e. a number between decimal 0 and decimal 255), with dots used to separate each part. For example, the IP-address for the web-server that provides access to the web-site of my company, Xamax Consultancy Pty Ltd, is 203.37.38.100.
Most people do not find it easy to remember long numeric addresses. A scheme called the Domain Name System (DNS) has been devised, which allows people to identify the roles that the hosts perform using more easily-remembered names instead of inconvenient numbers.
A single IP-address may be mapped to multiple names (i.e. several names can share the same numeric address, e.g. where multiple small companies share the same server). In addition, a single name may be mapped to multiple IP-addresses (i.e. several hosts may run servers that perform the same role at the same time, e.g. to share the load when heavy demand exists).
The DNS is hierarchical. For example, the name www.xamax.com.au/ corresponds to my company's web-server's IP-address of 203.37.38.100. It identifies a server (www), within a `domain' called `xamax.com.au/', which is in turn subsidiary to the larger domain `com.au' (intended for companies operating within Australia), within the yet larger domain of `au' (for Australia as a whole). The highest level of the hierarchy (e.g. .au) is referred to as a 'top level domain' (TLD). The second level (e.g. .com.au) is referred to as a 'second level domain' (2TLD).
Two different categories of `top-level domain' (TLD) exist.
One category is so-called `country-code TLDs' or ccTLDs, such as `au' for Australia, `uk' for the United Kingdom' and `us' for the United States of America. A ccTLD may be dependent on geography to the extent that the organisation that applies for a sub-domain within it (e.g. xamax.com.au) may be required to provide some evidence that it operates within that geographical area. However there is generally no requirement that the hosts on which the organisation's servers run be located in the geographical area indicated by the ccTLD (and, indeed, because of cost and network capacity considerations, they in many cases are not). In addition, where an organisation provides services to other parties, there is generally no requirement that those parties operate in the geographical area indicated by the ccTLD.
The policies in relation to allocation of sub-domains within com.au (established by AuDA, administered by INWW, and expressed at http://www.inww.com/policies/comaupolicy.php3) are among the most stringent in the world, in terms of the need to demonstrate justification for the claim to an association with the name requested: ÒOnly commercial entities registered and trading in Australia will be allocated a com.au domain nameÓ. Many other ccTLDs, however, appear not to be subject to tight constraints.
The other category of top-level domain is so-called `generic TLDs' or gTLDs, such as .com and .org. A gTLD is entirely independent of geography, and hence, for example, any company can apply for and be granted a name of the form <companyname>.com or <organisation>.org. For example, my company had every right to register xamax.com (except that a removalist company in Connecticut beat me to it). The various bodies involved in the registration process (ICANN, Internic and the various registrars) appear to have almost no policies in relation to the allocation of names, to the extent that almost anyone can register almost any name that is not currently registered to someone else.
When a message is to be sent over the Internet, it may be first broken into multiple `packets', and large messages usually are broken up in this way. The packets are then transmitted from the sending node, and the receiving node re-assembles them. The packets pass through intermediate nodes on the way, often a great many of them. A message transmitted from California to Sydney, for example, generally passes through between 15 and 25 nodes en route. Some years ago, I published a simplified description of this process using the analogy of a postal system. It is at http://www.rogerclarke.com/II/InternetPS.html.
The `route' taken by each packet varies depending, in particular, on precisely when it is sent, precisely where it leaves from, precisely where it is going to, and the traffic-load at the time on the many arcs close to its path. Most commonly, the path that any given packet follows from California to, say, Sydney, would pass through multiple computers in each of Australia and the U.S.A., and perhaps New Zealand, but other general paths are feasible, and the number of possible paths, already large, continues to increase.
I published an `Internet Primer' several years ago. It is at http://www.rogerclarke.com/II/IPrimer.html. More substantial descriptions are in text-books such as Stevens W.R. (1994) `TCP/IP Illustrated Vol 1', Addison-Wesley, 1994, and Stevens W.R. (1996) `TCP/IP Illustrated Vol 3: TCP for Transactions, HTTP, NNTP and the Unix Domain Protocols', Addison-Wesley, 1996.
The Internet is unlike any technology that has preceded it. Key differences are the following:
The Internet supports many services. Important examples are e-mail, file transfer and the World Wide Web. Some of these are primarily technical in nature, and enable computers to work together more effectively. Most, however, are directly designed to support the communication activities of people. There are several score such services, which enjoy varying degrees of popularity.
Each service available over the Internet is provided through specific `communications protocols' that define the engineering specifications, i.e. how each participant's device needs to behave. Important examples include:
Each of these services has its own characteristics. In particular:
Because of the very considerable differences among services, each service needs to be analysed in its own terms rather than being assumed to have the same characteristics as other services available over the Internet.
Internet services are provided by organisations conventionally referred to as Internet Services Providers (ISPs). A fundamental service is the provision of a connection to the Internet. An ISP that performs this service is usefully referred to as an Internet Access Provider (IAP). Some ISPs offer a wide range of functions, including access provision, e-mail services, the hosting of web-sites, the design of web-pages, and the acquisition of domain-names. Other ISPs perform only a limited set of functions, such as enabling a person or organisation to connect their computer to the Internet, together with e-mail services; or the hosting of web-sites, but without enabling the user to themselves connect to the Internet.
The World Wide Web (hereafter `the Web') is one particular service that is available over the Internet. It was invented in about 1990. The term `the Web' is used somewhat ambiguously, to refer sometimes to the technology, sometimes to the infrastructure that supports it, and sometimes to the widely distributed collection of files that is available over it. The Web has grown very rapidly since the mid-1990s, and now comprises software and content on literally millions of servers.
The Web enables a file to be stored on one computer connected to the Internet, in such a manner that a person using another computer connected to the Internet can request, receive and display a copy of it. The process involved is depicted in the following diagram:
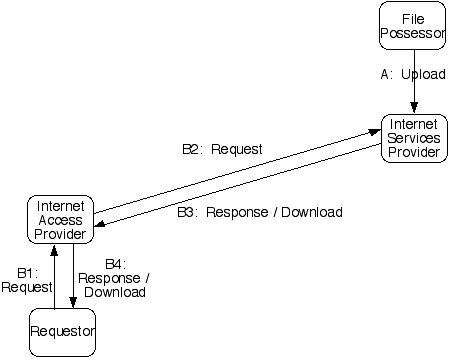
The process is as follows:
The terms conventionally used to refer to a file that is transmitted is a `document' or `web-page'. The location of a web-page is identified by a `uniform resource locator' (URL).
A collection of web-pages stored in a repository is referred to as a `web-site'.
A computer makes a web-site available by running server-software that is referred to as a `web-server'. A computer that requests and receives documents does so by means of client-software that is referred to as a `web-browser'.
Requests and responses are expressed in accordance with the communications protocol HyperText Transfer Protocol (HTTP). A request (or `GET' command) contains a small amount of information about the client, primarily the network-address of the host (its `IP-address'), the version of the web-browser being used, and some details about what data-formats it will and will not accept.
Documents may be created and stored in a form ready for downloading and display. The URL for such a readily-available web-page is a relatively simple format. The URL for my consultancy resumé, for example, is http://www.xamax.com.au/CV/RC.html. This comprises the string Òhttp://Ó (which declares the communications protocol to be used), the server-name (which is typically, but not always, `www'), the domain-name of the server (`xamax.com.au'), and the `path-name' of the file, comprising the file-name, preceded by any directories that the file is located within (`/CV/RC.html').
A web-site is commonly identified at the level of a server and domain-name, such as http://www.xamax.com.au; but in some circumstances it is conventional to refer to a sub-set of such a storage-area as a web-site, such as all items within a particular directory, e.g. my company's sub-collection of resumé information, at http://www.xamax.com.au/CV/.
Web-pages may include text, images, sound and/or video, and may be formatted in a variety of ways. The most common format is called HyperText Markup Language (HTML), which provides guidance to the web-browser as to how the content is structured and should be displayed.
HTML includes a feature conventionally called `hotlinks', whereby parts of a web-page may be contrived to point to other web-pages. If the user of the web-browser moves their mouse in order to position the cursor over a hotlink, and then clicks on the mouse-button, the web-browser sends a request for the web-page whose URL is pointed to by that hotlink. Alternatively, a hotlink may point to an e-mail address rather than to a URL. In this case, the web-browser generally passes the e-mail address to an e-mail client, and invites the user to compose and send an e-mail.
A web-page that is downloaded to a web-browser is, by default, only a temporary copy which disappears when the display in the browser-window is over-written by some other document, or the web-browser or the host on which the client is running is closed down. Many web-browsers operate a short-term store, however, so that the document can be re-displayed some hours or perhaps even days later, without having to again fetch it from the site from which it was originally downloaded. This is conventionally referred to as `local cache'. In addition, a requestor is generally able to save the document in a named file on the requestor's own machine. Nodes on the transmission path between the browser and the server may also cache pages that pass through them, and with popular pages may do so for an extended period.
A popular definition of the Web is provided by Encyclopædia Britannica at http://www.britannica.com/bcom/eb/article/7/0,5716,2517+1+2506,00.html?query=world%20wide%20web. Other sources include:
In addition, a vast array of resources is indexed on service-sites such as Yahoo's http://dir.yahoo.com/Computers_and_Internet/Internet/World_Wide_Web/.
The engineering specifications that underlie the Web are the responsibility of an industry association called the World Wide Web Consortium (W3C), at http://www.w3.org/. W3C's Technical Reports and Publications are at http://www.w3.org/TR/.
Particular characteristics of the Web are of significance to this matter. They are as follows:
This section examines the factors relevant to the determination of the place of publication of a web-site, by analogy with some previously existing communication technologies.
A first step is to identify communication technologies that are distinctly different from the Web. These include the following:
In each of these cases, the publisher actively and intentionally disseminates the material to the recipient.
The second step is then to identify communication technologies that evidence similarities to the Web, and that are therefore contenders as analogies from which an argument could be constructed. These include the following:
In determining the place of publication of a web-site, all analogies to prior publishing technologies are deficient. The least deficient comparison is with a library. This analogy is not at all apt in the case of access to holdings by a person making a visit to the library. It is a better fit in the case of access by borrowing from a library, in particular through inter-library loans, which enable access without the requestor having to pay a visit to the holding library.
A library analogy is still deficient, however, to the extent that:
This section further examines the factors relevant to the determination of the location or locations in which a web-page is published, but from a different perspective. Rather than arguing by analogy, it treats the Web as a distinctly different message communication technology from any that preceded it.
The primary consideration appears to me to be the act performed by the alleged publisher. An organisation may actively `push' material into a location, for example by arranging for it to be handed out, despatching it by mail to a consumer, physically delivering it to a bookshop or library, transmitting it over a broadcast medium to a receiver, or authorising its performance to an audience. On the other hand, a person may provide material in one location and another person might obtain a copy and then convey it to another location, for example by carrying a copy across the border, mailing it, or transmitting it by radio. In the second case, the original provider of information has not performed any act in the latter place. The copied information is `pulled' from the web-site as a result of the request. The web-server merely reacts to the request.
A person who causes a document to be stored on a web-server performs a positive act in the jurisdiction in which the host running the web-server is located. The operation of the web-server, on the other hand, involves responding to requests received. Those requests may come from any person irrespective of that person's location. They travel across a sometimes very long path. The transmission of copies of the document in response to requests is not the result of action by the originator, because it is initiated by the requestor. The process is reactive and is automated, and the software performing the function cannot ascertain across which jurisdictions the transmission will pass, nor in what jurisdiction the copy will be displayed, nor whether further copies will be made of it. A person who causes a document to be stored on a web-site in one jurisdiction takes no action whatsoever in a second jurisdiction if the document is later displayed there, and can neither know where it will appear, nor determine where it can or cannot appear.
The possibility exists that web-publishers could be required to `filter' requests, in order to ensure that people in jurisdictions in which the document might be alleged to be defamatory were denied access.
Legislatures and Governments in some countries, including the U.S.A. and Australia, have sought to impose requirements of this nature in criminal jurisdictions, in particular in relation to material that breaches laws relating to pornography and gambling.
The issue has been considered by the European Union, which has established a clear set of principles in relation to the responsibilities of publishers and Internet Services Providers, and required member-countries to give legislative authority to those principles by early 2002. See 'Directive 2000/31/EC on certain legal aspects of information society services, in particular electronic commerce, in the Internal Market', of October 2000, at http://europa.eu.int/eur-lex/en/lif/dat/2000/en_300L0031.html.
Imposing a requirement to filter requests would necessitate every Internet publisher in the world performing the following actions in respect of every document that they have ever published on the Web, and will ever publish on the Web:
In addition, imposing a requirement to filter requests would necessitate every Internet publisher in the world performing the following in respect of every request received by every web-server they operate:
The proposition that publishers determine the jurisdiction-of-origin of a request is technically totally impracticable. The data that is included in a request is very limited. In general, the data that could be used to infer the jurisdiction-of-origin of the requests is limited to the IP-address of the machine from which the request appears to come. From that IP-address, it may or may not be feasible to infer the country to which it is assigned (e.g. IP-addresses commencing with 203 could be treated as being within Australia). But because IP-addresses are assigned to organisations and do not have to be used within that organisation's country of domicile, such an inference would not be reliable, and would result in both false acceptances and false rejections.
Domain-names are equally unreliable, because ccTLDs such as `.au' do not necessarily signify that the node is within the country signified by the country-code, and gTLDs such as .com are non-specific as to country.
Moreover, within federations such as Australia, the United States, Canada, Germany, Austria, France and Switzerland, the specific State, Territory, Provincial, Land, Department or Cantonal jurisdiction cannot be inferred at all.
Beyond the impracticality is the ease with which requestors can circumvent the publishers' precautions. So-called `anonymising technologies' obscure the origin of the request, in most cases in an undetectable manner. To be effective in circumventing the control, all a requestor in a country that would otherwise be excluded has to do is to submit the request via an anonymising service that appears to be located in a country for which the document in question is approved. Such schemes already exist (e.g. Anonymizer at http://www.anonymizer.com/, AT&T's Crowds at http://www.research.att.com/projects/crowds/, Onion Routing at http://www.onion-router.net/, and ZKS's Freedom at http://www.zeroknowledge.com/). At this stage, they are not well-known nor highly used. If a senior Court of a leading nation such as Australia were to find that a web-page is published in any jurisdiction in which it is downloaded, the use of such anonymising services would very likely be stimulated.
A further means is available whereby a restrictive approach to the place of publication could be subverted. Jurisdictions exist in which defamation laws are relatively weak. These have been referred to by some writers as 'defamation havens', e.g. Martin B. (2000) 'Defamation Havens', First Monday (5, 3) 6 March 2000, at http://www.firstmonday.org/issues/issue5_3/martin/index.html. The argument has been put in academic circles that 'regulatory arbitrage' will result in jurisdictions with more attractive regulatory environments attracting business from neighbouring economies, e.g. Froomkin A.M. (1996) 'The Internet As A Source Of Regulatory Arbitrage', Symposium on Information, National Policies, and International Infrastructure, 29 January 1996, at http://www.law.miami.edu/~froomkin/articles/arbitr.htm. One of the probable outcomes of a finding that a document is published in any jurisdiction in which it is accessed is that web-servers would be placed in locations that act as 'defamation havens'. This would tend to undermine the ability of Australian courts to enforce Australian law in relation to materials that emanate from an Australian source.
Compliance with a requirement that a web-server filter requests, so that only some requests were responded to, would demand that every Internet publisher in the world expend vast amounts of expertise, time and money. The economics of net-publishing would change dramatically. The opportunity that the Web has created to enhance freedom of access to information would to this extent be lost.
By way of example, I consider my own position. Of the four web-sites that I operate, the following situations pertain:
The examples I have provided above are from personal experience. They are, however, typical of the difficulties that would be confronted by individuals who publish information on behalf of, respectively, associations, companies, and themselves.
I am an expert in Internet and Web technology, applications and implications; but I would be seriously challenged by both the nature and the scale of such a task. Web-publishing is now the domain of individuals, very few of whom would be capable of such an analysis.
The Internet in general, and the Web in particular, represent revolutionary communication technologies, whose impact and implications are immeasurably greater than those of, for example, VCRs. It appears very likely that music recording is going through a sea-change, as a result of the MP3 standard, and the Napster and Gnutella peer-to-peer (P2P) file-sharing services. The nature of publishing has changed irrevocably. It would impose an unworkable regime on Web publishers if, merely by placing a document on a web-site, they were held to be answerable to all defamation laws throughout the world.
This section considers the implications that would arise if it were found that a document is, for the purposes of the law of defamation, published in every jurisdiction in which it is downloaded.
The communication technologies that have been used during the twentieth century required considerable investment in infrastructure. They were accordingly controlled by large corporations. Those corporations were capable of undertaking professional examination of the consequences of their publications.
The new communication technologies unleashed by the Internet do not require substantial infrastructure, and are not capable of being controlled by large corporations. They are already available to individuals, and people throughout the world are availing themselves of the opportunities. This is resulting in an unprecedented degree of freedom of information, and in speed of reticulation of information. The effect of NATO bombardment on Serbia was reported over the Internet to the world, from within Serbia, with an immediacy (and an impunity) that makes films about World War II resistance fighters seem quaint.
A finding that a web-page is published wherever someone downloads it would therefore affect large corporations, small businesses, and myriad private individuals. They would all be forced to make a decision about every web-page they published and every jurisdiction in the world. To simplify their decision-processes, publishers may resort to measures such as:
Self-censorship by publishers, or exclusion of defamation-risk countries, would be seriously to the detriment of free and open societies generally. In particular, it may well be directly against the interests of Australians. Many U.S. publishers, especially the myriad small ones, might regard Australia as being a country that should be excluded, on the grounds that the defamation laws are complex, and vary considerably among the States.
More broadly stated, a finding that a web-page is published in every jurisdiction in which it is downloaded would have a 'chilling effect' on free speech, and hence a negative impact on democratic processes.
Simpson J. in Macquarie Bank Ltd v Charles Joseph Berg (Unreported, NSW Sup Ct, Simpson J, 2 June 1999, in Privacy Law & Policy Reporter 6, 2 (July/August 1999) 21) refused to restrain the publication of material over the Internet, on the basis that to do so would be to superimpose the NSW law relating to defamation on every other state, territory and country in the world.
The explanation provided by Simpson J. was that "It is reasonably plain, I think, that once published on the Internet, material is transmitted anywhere in the world that has an Internet connection [sic - in the case in question, which involved the Web, material may be so transmitted, but only in response to a request]. It may be received [sic - the action is better described as being 'acquired'] by anybody, anywhere, having the appropriate facilities. Senior counsel conceded that to make the order as initially sought would have had the effect of restraining publication of all the material presently contained on the website to any place in the world. Recognising the difficulties associated with orders of such breadth, he sought to narrow the claim by limiting the order sought to publication or dissemination 'within New South Wales'. The limitation, however, is ineffective ... Once published on the Internet, material can be received anywhere, and it does not lie within the competence of the publisher to restrict the reach of the publication".
Further, "An injunction to restrain defamation in NSW is designed to ensure compliance with the laws of NSW ... Such an injunction is not designed to superimpose the laws of New South Wales relating to defamation on every other state, territory and country of the world. Yet that would be the effect of an order restraining publication on the Internet. It is not to be assumed that the law of defamation in other countries is co-extensive with that of NSW, and, indeed, one knows that it is not. It may very well be that according to the law of the Bahamas, Tazhakistan [sic], or Mongolia, the defendant has an unfettered right to publish the material, To make an order interfering with such a right would exceed the proper lmits of the use of the injunctive power of this court".
The Internet in general, and the Web in particular, are communication technologies that differ in very significant ways from the technologies that preceded them. If the place of publication of a web-page is determined by reference to prior technologies, then the nearest (but far from perfect) analogy is with inter-library lending. If the place of publication is determined by reference to the positive acts of the publisher, then the place in which a web-page happens to be downloaded and displayed in a web-browser is not a place of publication because that downloading is not active so far as the publisher is concerned.
If, notwithstanding the above technical arguments, the Court were to find that the place in which a web-page is downloaded and displayed in a web-browser is a place of publication, then very serious practical difficulties arise for Internet publishers. The myriad of individuals who are now web-publishers could not comply with the varying defamation laws throughout the world.
Highly significant public policy implications arise. It would be to the serious detriment of freedom of access to information if Internet publishers had to be mindful of every defamation law in the world. For example, if Australian jurisdictions are identified as having a particularly stringent defamation law and a broad interpretation of place of publication, then Internet publishers, particularly in the U.S.A., may seek to exclude Australia from the range of possible recipients of Internet publications.
I originally addressed this issue in March 2001. I did so in the role of an expert witness requested by Dow Jones Inc. to answer a series of questions as it prepared its defence against a defamation suit in the Victorian Supreme Court by Joseph Gutnick. I addressed the issue again in July-August 2001. I was asked further questions by the legal team of Charles Berg when it was preparing its defence against a suit brought by Macquarie Bank.
This document reflects the contents of my affidavits in those two cases, for the most part very closely. The barristers and solicitors involved asked excellent questions, and forced me to clarify my explanations and analysis. I accordingly thank Geoffrey Robertson QC of London, Tim Robertson SC of Sydney, Paul Reidy partner of Gilbert & Tobin Sydney, Stuart D. Karle of Dow Jones in New York, and Ross Dalgleish barrister of Sydney. I also thank my sometime colleague and co-author Ooi Chuin Nee, whose depth of technical knowledge of the Internet is vastly greater than mine, and who has tolerated many inadequately clear questions and poor first drafts of many segments of text. But any bouquets and brickbats should be aimed at me.
| Personalia |
Photographs Presentations Videos |
Access Statistics |
 |
The content and infrastructure for these community service pages are provided by Roger Clarke through his consultancy company, Xamax. From the site's beginnings in August 1994 until February 2009, the infrastructure was provided by the Australian National University. During that time, the site accumulated close to 30 million hits. It passed 65 million in early 2021. Sponsored by the Gallery, Bunhybee Grasslands, the extended Clarke Family, Knights of the Spatchcock and their drummer |
Xamax Consultancy Pty Ltd ACN: 002 360 456 78 Sidaway St, Chapman ACT 2611 AUSTRALIA Tel: +61 2 6288 6916 |
Created: 23 March 2001 - Last Amended: 2 October 2001, with minor revisions 2 June 2002 by Roger Clarke - Site Last Verified: 15 February 2009
This document is at www.rogerclarke.com/II/DefWeb01.html
Mail to Webmaster - © Xamax Consultancy Pty Ltd, 1995-2022 - Privacy Policy