Roger Clarke's Web-Site
© Xamax Consultancy Pty Ltd, 1995-2024

Infrastructure
& Privacy
Matilda
Roger Clarke's Web-Site© Xamax Consultancy Pty Ltd, 1995-2024 |
|
|||||
| HOME | eBusiness |
Information Infrastructure |
Dataveillance & Privacy |
Identity Matters | Other Topics | |
| What's New |
Waltzing Matilda | Advanced Site-Search | ||||
Principal, Xamax Consultancy Pty Ltd, Canberra
Visiting Fellow, Department of Computer Science, Australian National University
Gillian Dempsey, Department of Commerce, Australian National University
Ooi Chuin Nee, Electronic Trading Concepts - ETC, Sydney
Robert F. O'Connor, Departments of English and Commerce, Australian National University
Version of 15 February 1998
© Xamax Consultancy Pty Ltd, 1997, 1998
Available under an AEShareNet ![]() licence
licence
This document is at http://www.rogerclarke.com/II/IPrimer.html
This document provides an introduction to Internet technology, designed to enable discussion of strategic and policy matters. It commences with an explanation of the various elements of Internet infrastructure, which comprises architecture, protocols, and software. The process is then described whereby the infrastructure is used to transmit messages. A complementary document contains a simplified description of Internet processes based on a postal service analogy.
4. Software That Implements Internet Protocols
6. The Process of Using the Internet
The purpose of this document is to provide a description of Internet technology that is accessible by non-technologists, and is as short as practicable, but provides a firm foundation for discussions concerning strategic and policy aspects of the Internet. Examples of such topics are crime prevention, regulation, censorship, electronic publishing and electronic commerce generally.
The Internet is currently the focus of a great deal of attention. In due course, however, it may come to be seen as a special case of a more general concept of 'information infrastructure'. Documents that provide introductory information concerning the information infrastructure are at Clarke (1994), Clarke (1995) and Clarke (1997).
Newcomers to the Internet may be well-advised to first read a companion, introductory document that provides an explanation of the process whereby Internet messages are transmitted. This uses the metaphor of the Internet as a special kind of postal service.
This document commences with a description of the elements of Internet technology, referred to collectively as infrastructure. The main body of the paper deals in succession with the following aspects of Internet infrastructure:
A description is then provided of the process whereby the infrastructure is used in order to transmit messages of various kinds.
The Internet comprises a network of computer networks, which transmit messages to one another using a common set of communications protocols, or sets of operating rules. Networks comprise addressable devices or nodes (computers) connected by arcs (communication channels).
Nodes can be differentiated according to the services they provide. They include:
Nodes are not limited to performing a single role; for example, some workstations may also be configured to act as servers for other workstations, and even as routers. For each of the roles that a particular node performs, it is assigned a unique identifier, called an IP-address.
The communication channels that connect nodes may be implemented using any of a number of technologies. These include various forms of physical medium, such as copper wire (`twisted-pair'), co-axial cable and fibre-optic cable; and wireless, electromegnatic transmission either at low-level, such as microwave links and cellular mobile networks, or via satellite.
Any node can transmit a message to any other node, along the communications channels, via the intermediating nodes.
There is no constraint on the patterns whereby communication channels can connect nodes. User workstations are in most cases connected to only one other node, but host-servers and especially intermediating nodes may be connected to multiple other Internet nodes. Because of this feature, there are generally many different paths between any two Internet nodes. This is very different from a hierarchical network, in which each node is connected to just one parent, because it provides redundancy, and hence enables the network as a whole to continue to function even when some of its nodes and channels are out of action.
Each pair of nodes is able to communicate because their behaviour is designed to conform to clearly-defined sets of rules. These are most usefully described as the Internet Protocol Suite, but are most commonly known by the combined acronyms of the two most critical protocols, TCP/IP.
The protocols are implemented in software that runs on each node. For the purposes of this document, the following classes of software are usefully distinguished:
Internet governance is a collaborative undertaking, rather than one planned and controlled in a hierarchical manner. To the extent that a hierarchy of authority exists for Internet architecture, it comprises:
In addition, the Internet Society (ISOC) is a "professional membership organization of Internet experts that comments on policies and practices and oversees a number of other boards and task forces dealing with network policy issues". An Australian affiliate is active, ISOC-AU.
The following sections deal in succession with the protocols and the software that implements them. Building on this foundation, the final section then describes the process whereby the architecture, protocols and software are used to transmit messages.
This section examines the protocols that underpin the Internet. It comprises:
The term protocol is used to refer to the set of rules that govern the communications between nodes.
A wide number of functions need to be performed, and hence there is a considerable number of protocols. The complete family of protocols is referred to as the Internet Protocol Suite. Sometimes the family is referred to by the combined names of just the two most important protocols, TCP/IP.
To simplify matters, the functions are organised into a series of layers. The lower layers perform deep-nested, technical functions. The upper layers assume that the lower-layer functions work reliably, without concerning themselves about how they are performed. This greatly reduces the complexity of each protocol and of each piece of software that implements each protocol. It also enables functionally equivalent protocols and software products to be substituted for one another.
The deepest-nested layer is concerned with direct interaction between the node and the communications channel. It results in a signal being transmitted on a channel. Higher-level layers interpret the signals to have information content. The lowest level is concerned with binary digits, usually abbreviated to bits. The combination of a succession of eight bits into a byte provides a convenient means of representing up to 256 symbols, such as letters, decimal digits and punctuation marks. Larger sets of symbols (such as the thousands of Chinese and Japanese ideograms) require larger combinations, such as two-byte chunks. At higher levels, groups of bits or bytes are clustered into groups called packets or datagrams. A set of one or more packets is used to represent a message which is directly useful to people.
This may seem very long-winded. The reason for the message-packet-byte-bit-signal structure is that people and communication channels have very different characteristics and limitations. The structuring enables those differences to be reconciled, and for software tools at each level to be relatively simple, and hence reasonably reliable.
The Internet Protocol suite is made up of 4 layers, as depicted in Exhibit 3-1.
Layer Function Orientation Examples
Application Delivery of data to Messages HTTP, SMTP, FTP
an application
Transport Delivery of data to Messages and TCP
a node Segments
Network Data addressing and Segments and IP
transmission Packets
Link Network access Packets, Bits Ethernet, PPP
and Signals
The following sub-sections provide brief descriptions of each of these layers, commencing at the highest level and working down to the lowest.
The application layer protocols handle messages that are to be interchanged with other applications in nodes elsewhere on the Internet. They specify such details as the sequence and format of the data-items. The protocols include:
The transport layer protocols specify whether and how the receipt of complete and accurate messages is to be guaranteed. In addition, if the message is too large to be transmitted all at once, it specifies how the message is to be broken down into segments.
There are two major transport layer protocols:
A separate document provides an explanation of the TCP Protocol.
The network layer protocols specify how packets are moved around the network. This includes the important questions of how to address the node that is being sought, and how to route each packet to that node.
The key protocol at this level is IP (Internet Protocol). Other protocols at this level, which are closely related to and dependent on IP, include:
A separate document provides an explanation of the IP Protocol.
The link layer protocols specify how the node interfaces with the communications channel. They convert the bits that make up packets into signals on channels. Through a physical `port', socket or plug (e.g. a serial RS-232 or RJ-11 port, or a parallel port), they transmit a signal onto a channel provided by a medium such as twisted-pair copper wire, co-axial cable, optical fibre cable, or a digital cellular `mobile phone' network.
Commonly used link layer protocols include:
Link-layer protocols are implemented in software that is commonly referred to as a device driver and may be embedded in a network interface card.
Each role that each node on the Internet performs is uniquely identified by an IP-address. However, IP-addresses are difficult for people to remember. Each host is accordingly also known by one or more host-names, which corresponds, or `maps to', to its IP-address. Whereas 204.123.2.2 is difficult to remember, for example, gatekeeper.dec.com is mnemomic, and much easier. The string `dec.com' identifies a `domain', and the string `gatekeeper' identifies a particular host within that domain.
The mechanism whereby the correspondences or `mappings' are maintained is called the Domain Name System (DNS). DNS is a hierarchical name-space used to map hostnames to IP-addresses and vice versa.
"The root of the system is unnamed. There are a set of what are called `top-level domain names' (TLDs). These are the generic TLDs (EDU, COM, NET, ORG, GOV, MIL, and INT), and the two letter country codes from ISO-3166. ... Under each TLD may be created a hierarchy of names. ... Many organizations are registered directly under the TLD, and any further structure is up to the individual organizations. In the country TLDs, there is a wide variation in the structure, in some countries the structure is very flat, in others there is substantial structural organization. In some country domains the second levels are generic categories (such as, AC [=academic], CO [company], GO [government], and RE [research]), in others they are based on political geography, and in still others, organization names are listed directly under the country code" ( RFC1591). Exhibit 3-2 provides a graphical presentation of part of the domain-name hierarchy.
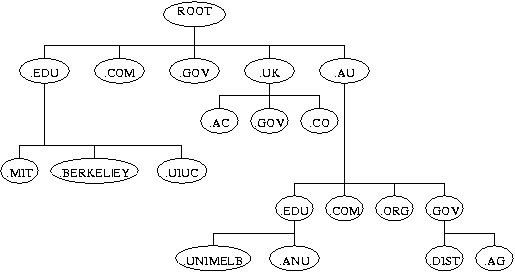
DNS hierarchy
The machine on which this document is stored has the host-name `www.anu.edu.au', which signifies a host identified as `www' within the low-level domain `anu' (for Australian National University), within the upper-level domain `edu' (for education), with the TLD `au' (for Australia). The corresponding IP-address for that host-name is 150.203.205.12. It should be noted that more than one host-name can be mapped to one IP-address. For example, www.anu.edu.au is also known as online.anu.edu.au and boomer.anu.edu.au. Moreover, Internet Services Providers such as ozemail and connect.com provide host-name services for many companies' web-pages. In addition, a single host-name can be mapped to more than one IP-address, e.g. by using a load-balancing feature called `DNS round robin'.
Nodes that are permanently and directly connected to the Internet generally have a persistent host-name and IP-address. Some IP-addresses, however, are associated with particular computers only temporarily, using `dynamic IP-address allocation'. This is normal in the case of dial-up connections using SLIP or PPP link-layer protocols, but also in many local area networks using such protocols as Ethernet.
The mapping between host-names and IP-addresses is performed by software, without human intervention. During the Internet's early years, the software used a single master-file. The file was maintained centrally, and the up-to-date version was downloaded by all the hosts from time to time. This approach scaled very badly as the number of hosts on the Internet increased: it was unwieldly to handle, it used a lot of network bandwidth, and changes took a long time to take effect. Since the late 1980s, DNS information has not been held centrally in one location, but is instead distributed across thousands of servers all over the world, each of which is maintained independently. ( RFC1034 aka STD13).
Here is an example of how DNS is used. When someone who is currently in the .mit.edu domain (operated by the Massachusetts Institute of Technology) tries to do a lookup on www.anu.edu.au, the DNS resolver (the DNS client software) sends a request to the local MIT DNS server. This DNS server finds that it is an address which is not local to the domain, so it looks up the root server to find the authoritative server for the .au domain. The IP-addresses of all the root servers in the world should already be configured in every DNS server. The MIT DNS server then sends a query to the .au server to find the authoritative server for the .edu.au domain and in turn, queries the .edu.au server for the address for the .anu.edu.au domain. It then sends the query for www.anu.edu.au to the authoritative .anu.edu.au DNS server, at 150.203.1.10.
The overall authority for domain names, IP-addresses, and many other parameters used in Internet technology is the Internet Assigned Numbers Authority (IANA). However, "the day-to-day responsibility for the assignment of IP-addresses ... and most top and second level Domain Names are handled by the Internet Registry (IR) and regional registries" ( RFC1591).
The regional registry functions are performed by the various Network Information Centers, including the North American Internic, the old Australian Aunic, and the new Asia-Pacific apnic.
Allocation of names within TLDs is undertaken in a variety of different ways. Within the TLD .au (Australia), the registry function is coordinated by a specific-purpose entity, Australian Domain Name Administration Ltd (ADNA). This allocates operational responsibility for each high-level domain within the .au name-space. At present, for example, the .com.au space is managed by a company spawned by Melbourne University, Melbourne IT. Allocation of domain names has become a highly emotionally charged topic, particularly within the .com domains.
Public access to the databases of domain-names, registered owners, and IP-addresses, is provided by regional Network Information Centers. For the .au name-space, this is the APNIC search facility. These arrangements may change in the near future.
Because of the dramatic growth-rates that have occurred in the numbers of Internet nodes, the name-space is very crowded, and in danger of being exhausted. To cope with the situation until a revised domain- and host-name standard is implemented, interim strategies are in use (e.g. RFC 1918).
Internet protocols are implemented by software that runs in all Internet nodes, including workstations, hosts and intermediating nodes. In some cases, the software that implements a particular protocol may be a standalone tool, in others it may be a function within application software, and in others it may be embedded within systems software. Moreover, a particular piece of software may implement protocols in only one layer, or in several.
It is common for the following kinds of application software running in users' workstations to implement the following protocols:
Hosts, which provide services for client workstations may, depending on their purpose, run other applications such as:
Intermediating nodes may run DNS servers.
On client workstations, a control panel (e.g. TCP/IP on a Mac, and Network under Windows 95) is used to specify parameters necessary for the TCP and IP tools to function appropriately.
On nodes that are being used as routers, utilities are provided that allow additional routing rules to be specified, e.g. the route command on most Unix systems.
On Macs, the control panel PPP enables the user to set up the appropriate parameters for PPP, such as modem speeds and the telephone number to dial. Equivalent capabilities are provided for Windows 95 under Dial Up Networking settings.
Software depends on computers to execute it, and communications depend on networking hardware. The hardware that represents the Internet's nodes and channels is not further discussed in this document.
In order to provide an adequate insight into the means whereby the architecture, protocols and tools are used, this section offers several descriptions, at different levels of abstraction and technical detail. These comprise:
An application program generates the contents of a message. It passes this to software that implements a high-level applications protocol (such as HTTP for web-messages), which wraps the contents in an envelope containing administrative data. (An alternative depiction is that it adds a header to the contents. At this level of abstraction, either expression is sufficiently accurate).
The application-layer software then passes the enveloped message to software that implements the TCP protocol, which prepares the message for placement on the net, and (depending on the message's size) may break it into segments. The TCP software then passes the multiply-enveloped content to software that implements the IP protocol, which completes the enveloping process, and addresses each packet to the intended recipient host.
The IP software passes each packet to link-layer software, which causes signals that represent the packets to pass across the communications channel.
Intermediate nodes pass the packets on to a node closer to the target-node. In the process of doing so, they may break the packets down into smaller packets.
In the recipient-node, the signals that arrive over the channel are re-interpreted as packets. The packets are passed up through the layers corresponding to the link-layer, IP, TCP and (for example) HTTP protocols, with each successive piece of software processing the data on the envelope that is intended for it. IP deals with the individual packets, without regard to the message that they belong to. The TCP layer ensures that all packets have arrived, and that the complete message is able to be re-assembled.
Finally, the unwrapped and re-assembled message is passed to the appropriate application.
The following repeats the preceding depiction in more structured, and more technically accurate, form:
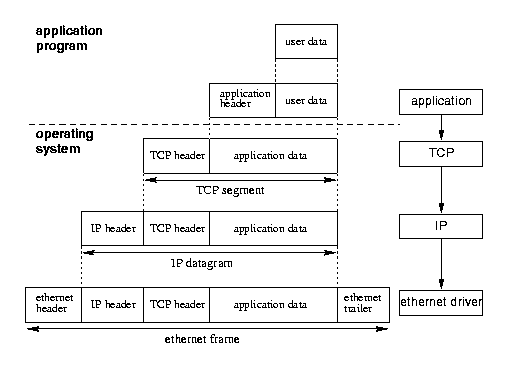
Source: Stevens 1994, p.10
This simplified description assumes that suitable software exists at all nodes within the paths that are followed by packets that make up the message. It also intentionally omits:
The complexity of the process is likely to appear very strange to the newcomer. The reason it is as it is, is because this provides enormous flexibility and resilience. There is no central element on which the Internet depends. Once the operation was commenced, many different nodes can perform the functions needed to keep it operational; and provided that enough channels are functioning, traffic can continue to reach its target, even though many of the channels and nodes may be out of action.
This example shows how an electronic mail message is sent over the Internet using the application-layer protocol SMTP. This example deals with the simple example, where the target host is directly contactable by the sending host, and thus, the message will not have to go through any intermediate relay message transfer agents (MTAs).
Alice wants to send an email message to Bob so she starts up her mail user agent (UA, which is the generic term for an e-mail client such as Eudora or MS-Mail). She uses her UA to create a message containing the following text:
To: Bob <bob@wombat.foo.com> From: Alice <alice@bar.acme.com> Subject: Happy Birthday Wishing you a happy birthday Alice
Alice then instructs her UA to send the message.
Alice's host (bar.acme.com) first sends a DNS query to its local DNS-server to resolve the IP-address for Bob's host (wombat.foo.com) into its IP-address. Alice's host (bar.acme.com) then establishes a TCP connection with the port for SMTP (port 25) at that IP-address. The message is split into one or more TCP-segments, the segments are encapsulated in IP-datagrams, and those packets are passed to software that implements an appropriate link-layer protocol, in order to be sent to Bob's host (wombat.foo.com).
When the packets arrive at Bob's host (wombat.foo.com), the headers are removed and the resulting TCP-segments are then passed on to the TCP layer. The TCP layer removes the TCP header, and based on the information in the header, passes the resulting data on to the application that is bound to port 25 on the host, which in this case is the SMTP daemon. The SMTP daemon then places the message in Bob's mail-box, to await his attention.
To implement the process describe above, the following is the exchange that takes place between the user agent (UA, e.g. Eudora) and the receiving MTA:
[MTA to UA] 220 wombat.foo.com ESMTP Sendmail 8.8.5/8.8.5; Fri, 6 Feb 1998 13:43:50 +1100
[UA to MTA] HELO bar.acme.com
[MTA to UA] 250 wombat.foo.com Hello bar.acme.com [192.168.0.2], pleased to meet you
[UA to MTA] MAIL FROM:<alice@bar.acme.com>
[MTA to UA] 250 <alice@bar.acme.com>... Sender ok
[UA to MTA] RCPT TO:<bob@wombat.foo.com
[MTA to UA] 250 <bob@wombat.foo.com>... Recipient ok
[UA to MTA] DATA
[MTA to UA] 354 Enter mail, end with "." on a line by itself
[UA to MTA] Message-Id: <19980206123454.007e3600@bar.acme.com>
Date: Fri, 06 Feb 1998 12:34:54 +1000
To: <bob@wombat.foo.com>
From: <alice@bar.acme.com>
Subject: Happy Birthday
Mime-Version: 1.0
Content-Type: text/plain; charset="us-ascii"
Wishing you a happy birthday
Alice
.
[MTA to UA] 250 NAA22112 Message accepted for delivery
[UA to MTA] QUIT
[MTA to UA] 221 wombat.foo.com closing connection
Where the target-node is not directly contactable by the sending host, the message has to be passed through intermediating or relay MTAs. The sending host (bar.acme.com) does not need to know the complete route to the recipient (wombat.foo.com); all it needs is the address of the next hop to which to send the packets. The link-layer destination address is set to that of the next MTA but the destination IP-address is set to that of the ultimate recipient. Each intermediate node forwards the packets to a node closer to the target-node, until they reach their destination.
A separate document provides a sample trace of a HTTP session, including dumps of the datagrams sent in the session.
Other popular renditions of the structure and workings of the Internet can be found at a variety of locations such as ISOC and Yahoo.
More technical discussions are to be found in Stallings (1994), Stevens (1994, 1996) and Tannenbaum (1996).
The technical specifications are expressed in Internet Standards (which have an STD prefix), and Draft Standards, discussion documents and informational documents, which are generically referred to as `Requests for Comments' (RFCs). These are to be found at Internic.
Access to semi-official histories of the Internet (and, by the Internet's very nature, there can be no such thing as `the official history') is provided by ISOC.
Clarke R. (1994) 'Information Infrastructure Policy Issues' Policy 10,3 (Spring 1994), at http://www.rogerclarke.com/II/PaperIIPolicy.html
Clarke R. (1995) 'The Strategic Significance for Business and Government of Information Infrastructure and Technoculture' Proc. Conf. East Asian Conf. on Infrastructure for the 21st Century, Kuala Lumpur, 2 May 1995, at http://www.rogerclarke.com/II/KLII.html
Clarke R. (1997) `Regulating Financial Services in the Marketspace: The Public's Interests ', Proc. Conf. 'Electronic Commerce: Regulating Financial Services in the Marketspace', Sydney, 4-5 February 1997, at http://www.rogerclarke.com/EC/ASC97.html
Frisch (1995) `Essential System Administration', 2nd Edition, O'Reilly & Associates, 1995
Garfinkel, S. & G. Spafford (1996) `Practical Unix and Internet Security', 2nd Edition, O'Reilly & Associates, 1996
RFC1034 (1987) `Domain Names Concepts and Facilities', November 1987, at http://www.isi.edu/in-notes/rfc1034.txt
RFC1400 (1993) `Transition and Modernization of the Internet Registration Service', March 1993, at ftp://rs.internic.net/rfc/rfc1400.txt
RFC1591 (1994) `Domain Name System Structure and Delegation', March 1994, at http://www.isi.edu/in-notes/rfc1591.txt
Stallings W. (1994) `Data and Computer Communications', 4th Edition, Macmillan, 1994
Stevens W.R. (1994) `TCP/IP Illustrated Vol 1', Addison-Wesley, 1994
Stevens W.R. (1996) `TCP/IP Illustrated Vol 3: TCP for Transactions, HTTP, NNTP and the Unix Domain Protocols', Addison-Wesley, 1996
Tanenbaum (1996) `Computer Networks', 3rd edition, Prentice-Hall, 1996
| Personalia |
Photographs Presentations Videos |
Access Statistics |
 |
The content and infrastructure for these community service pages are provided by Roger Clarke through his consultancy company, Xamax. From the site's beginnings in August 1994 until February 2009, the infrastructure was provided by the Australian National University. During that time, the site accumulated close to 30 million hits. It passed 65 million in early 2021. Sponsored by the Gallery, Bunhybee Grasslands, the extended Clarke Family, Knights of the Spatchcock and their drummer |
Xamax Consultancy Pty Ltd ACN: 002 360 456 78 Sidaway St, Chapman ACT 2611 AUSTRALIA Tel: +61 2 6288 6916 |
Created: 2 November 1997 - Last Amended: 15 February 1998; addition of FfE licence 5 March 2004 by Roger Clarke - Site Last Verified: 15 February 2009
This document is at www.rogerclarke.com/II/IPrimer.html
Mail to Webmaster - © Xamax Consultancy Pty Ltd, 1995-2022 - Privacy Policy